

Gartner Low Code : Décryptage du Magic Quadrant et Prévisions du Marché
Dans l’univers technologique, peu d’institutions ont autant d’influence que Gartner. Lorsque


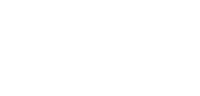
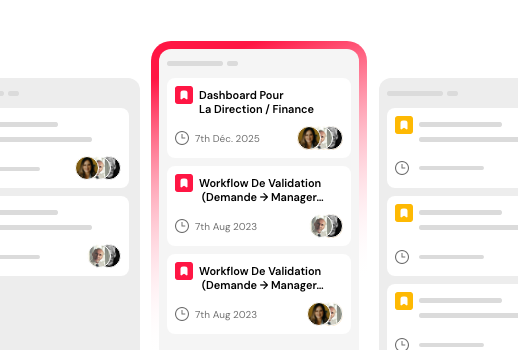
Utilisez des widgets par glisser-déposer pour créer une interface réactive.
Paramétrez et implémentez vos applications métier et visualisez vos processus

Testez et déployez vos processus métier en un clic et managez vos versions

Surveillez et contrôlez vos processus grâce au module de supervision
Merci pour votre inscription









Facile à mettre en place, à interfacer, à utiliser et à déployer. Équipe compétente, à l'écoute et réactive. Bref, je recommande vivement !
Cédric DEGREMONT